Reprenons la série des articles traitant des différents réseaux de neurones. Dans cet article, je vais t’expliquer comment fonctionne un réseau de convolution.
Dans l’article précédent, nous avions vu comment fonctionnait un réseau de neurone artificiel. Si tu n’as jamais entendu parler du fonctionnement, je te conseille de le lire avant de continuer. Comme je l’ai déjà expliqué, même en simplifiant, il y a une partie « technique » et « représentative » que je ne peux pas soustraire à l’explication. Je vais essayer de mettre le plus d’illustration possible pour bien comprendre. Chaque réseau à sa spécialité, ils ont des fonctionnements différents avec des résultats plus ou moins performants. Les réseaux de convolution sont très bons pour l’analyse des images.
Réseau de convolution
Je ne vais pas faire de l’histoire sur la création, ni qui, Wikipédia s’y prête très bien pour ce genre d’information. Allons dans la technique et pragmatique tout de suite ! Toujours en quatre étapes.
Conception en 4 étapes
Réseaux de neurones
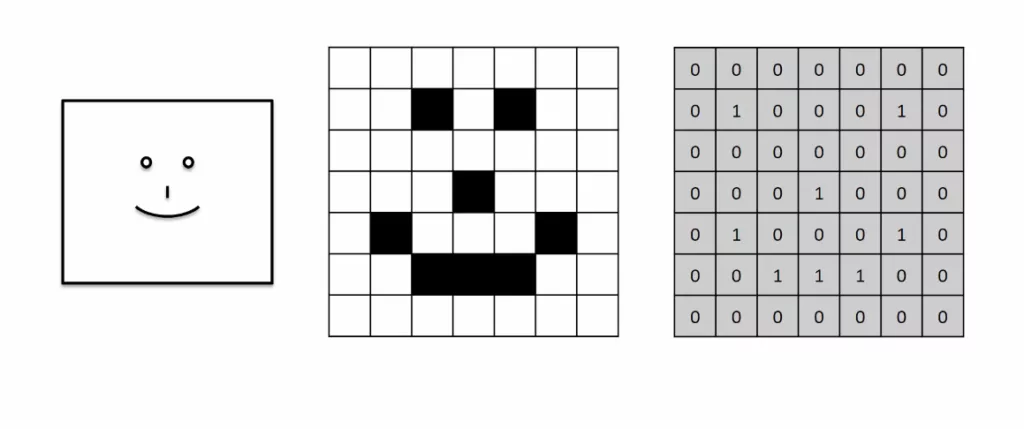
Une image est composée de petits carrés que l’on nomme « pixel ». Dans une image en noir et blanc, nous parlerons de 2 dimensions (array) car il y a blanc et noir. De plus, chaque pixel aura une valeur comprise entre 0 et 255 nuances de « gris » (rien à voir avec le film). Le blanc est représenté par le 0.
Pour une image en couleur, elle aura trois dimensions (array), repartie en 3 couleurs primaires, bleu, vert et rouge. Idem avec 255 nuances. Pourquoi 0 et 255 ? Selon mes recherches, c’était l’ensemble du code couleur RGB des écrans dans les années 80, les chercheurs ont gardé cette base.
Voilà une manière de comment l’ordinateur voit une image. Pour faire simple il n’y a pas de nuance dans les futurs exemples, c’est soit blanc donc 0 soit noir 1.
Convolution
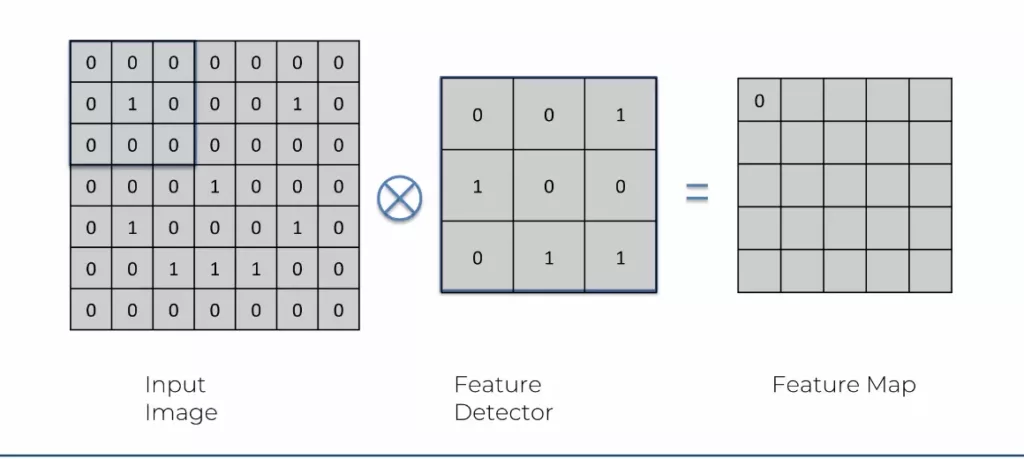
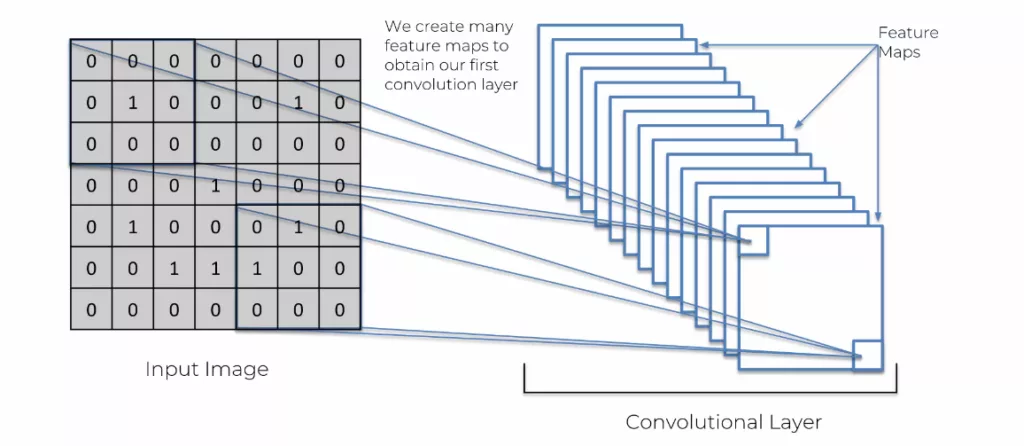
Pour la convolution, il suffit de reprendre l’image pixelisée, carré par carré, et de la « convertir » avec une sorte de « calque ». Oui, j’utilise beaucoup de guillemets, car aucun de ces termes sont utilisés. Le calque s’appelle un feature detector et l’image convertie se nomme feature map. Il existe des millions de feature detector différents et de taille différente, le choix se fait en fonction des best practice des data scientist. Une fois que l’image est intégralement passée par un feature detector, on obtient une feature map. C’est l’image originale, compressée une nouvelle fois avec un calque précis.
Voici en image :
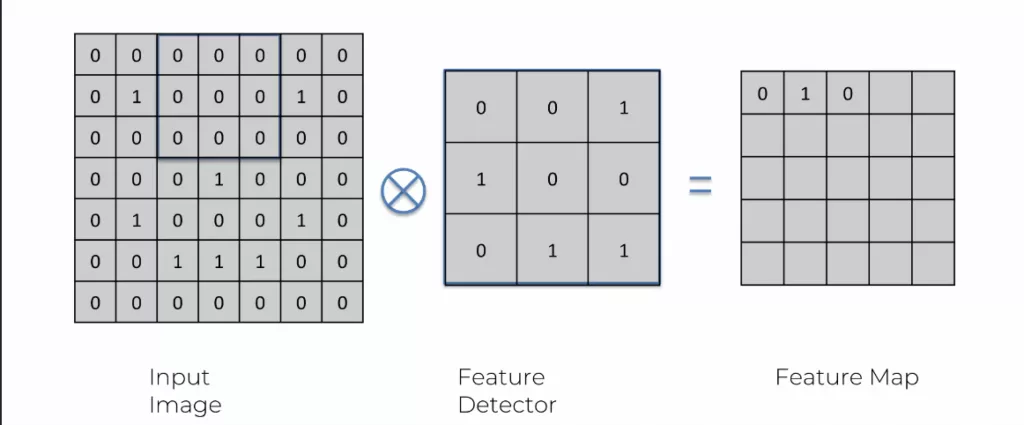
Nous répétons ce processus avec d’autres feature detector pour créer plusieurs feature map de cette image. Cela va créer une sorte de mille-feuilles de plein de feature map différentes. On appelle cela une couche de convolution.
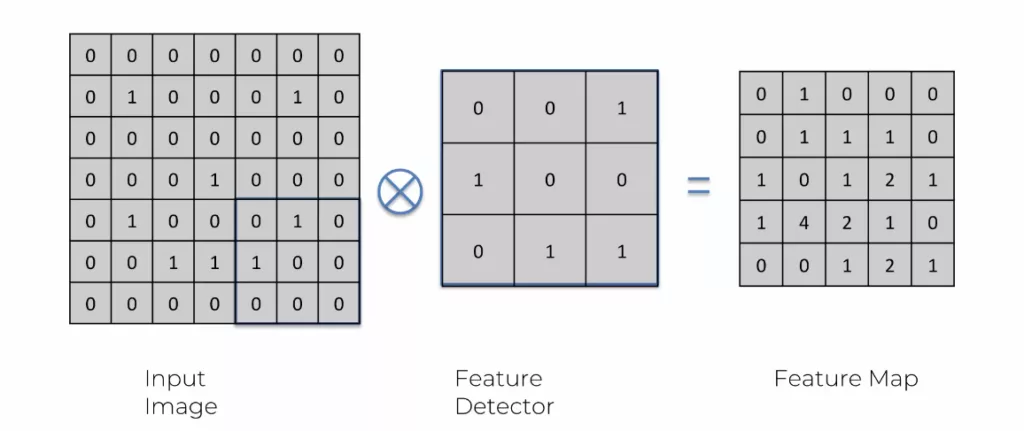
Voici le résultat de la feature map avec ce feature detector :
Dans ce site, tu écris avec ta souris un chiffre dans la barre en haut à gauche. Avec le pointeur de ta souris, tu peux voir les 7 couches de convolution comment elles travaillent. Elle détermine ce que tu as écrit en fonction de tout ce traitement d’image.
Max Pooling
Le réseau de neurone doit avoir une invariance spatiale. Notre cerveau est vraiment très fort, car sur les images ci-dessous, nous sommes capables de comprendre que c’est un guépard. Et cela peu importe si l’image est tordue ou non. De même, si le guépard est en premier plan, allongé, en train de courir, quoi qu’il en soit, on le reconnait au premier coup d’œil.

Nous le faisons de manière naturelle et nous n’avons pas l’impression que notre cerveau travaille dur. Ainsi, nous devons adapter l’algorithme de la machine pour qu’elle soit capable de faire comme nous. Si l’image est tordue, cela peut donner un résultat totalement différent. Idem, nous reconnaîtrons l’animal, qu’il soit assis, nous regarde, ou de dos, qu’il soit au premier ou second plan !

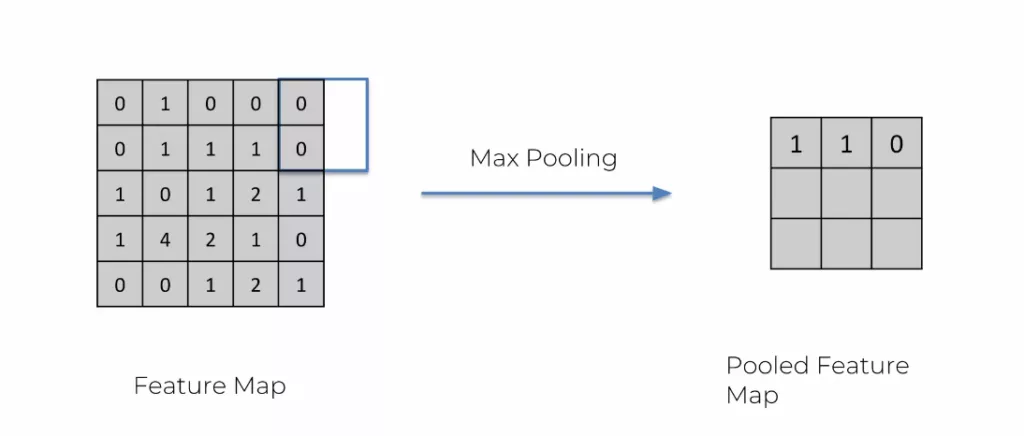
Pour limiter les erreurs, le max pooling est la même manipulation que pour obtenir une feature map.
On passe la feature map dans un max pooling (ici d’un carré de 2 par 2) où l’on va garder par exemple que les chiffres les plus grands. L’image encore réduite s’appelle un pooled feature map.
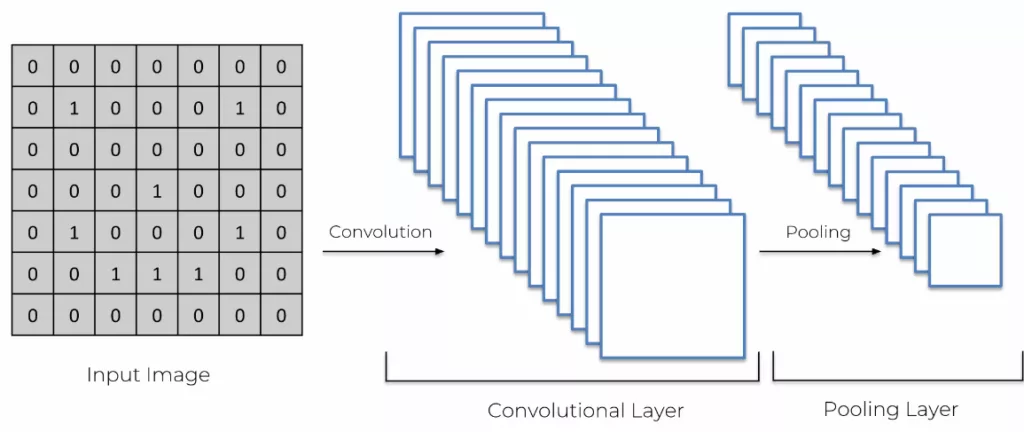
Idem que pour les features map, on va multiplier les max pooling pour obtenir un mille-feuilles de pooled feature map. Ainsi la machine va comprendre qu’il y a un pattern, un motif qui se présente souvent au même endroit et que cela fait partie de l’animal en question.
Flattening
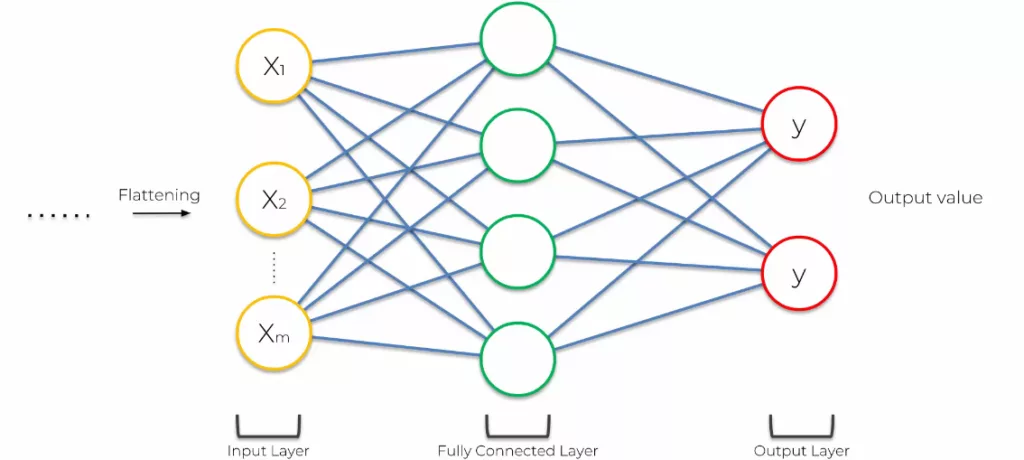
Comme nous l’avions vu précédemment, un réseau de neurone connecté, les couches d’entrées, cachées, et de sorties sont verticales. Jusqu’à maintenant, nous avions une image représentée par des carrés. Nous avons diminué la taille de l’image. Le Flattening permet de verticaliser les pooled feature map.
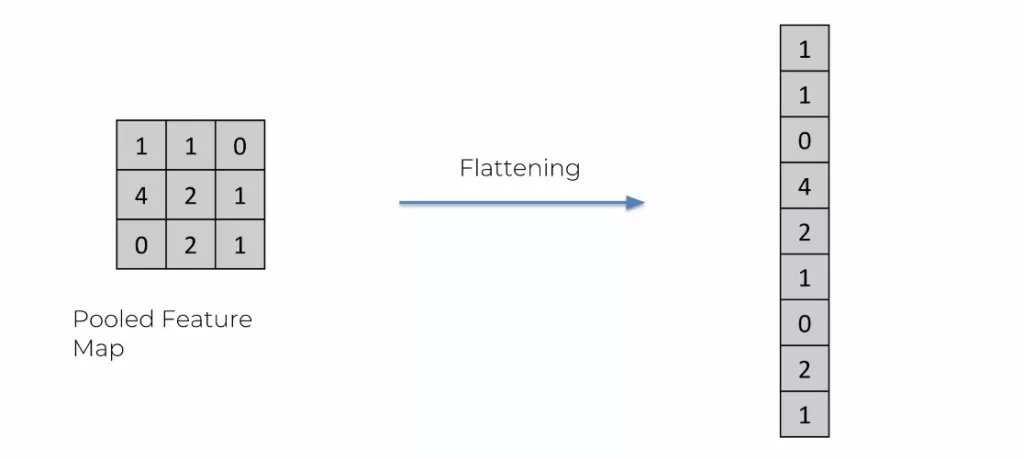
Et ensuite l’addition de l’ensemble des pooled feature map deviennent les entrées pour le réseau de neurone.
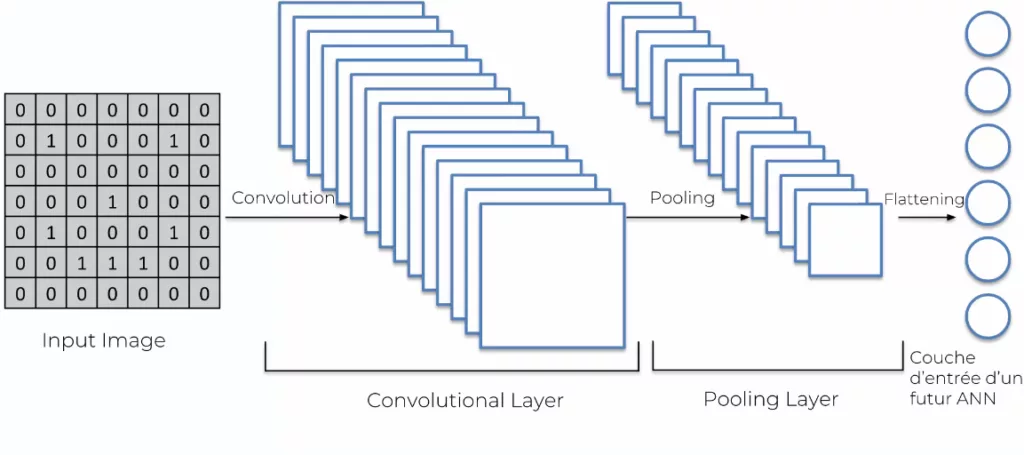
Couche entièrement connectée
Nous arrivons au bout. Si nous devions schématiser le travail accompli jusqu’à maintenant et que nous voulions apprendre à la machine à reconnaître un chien d’un chat, voici ce que ça donne :
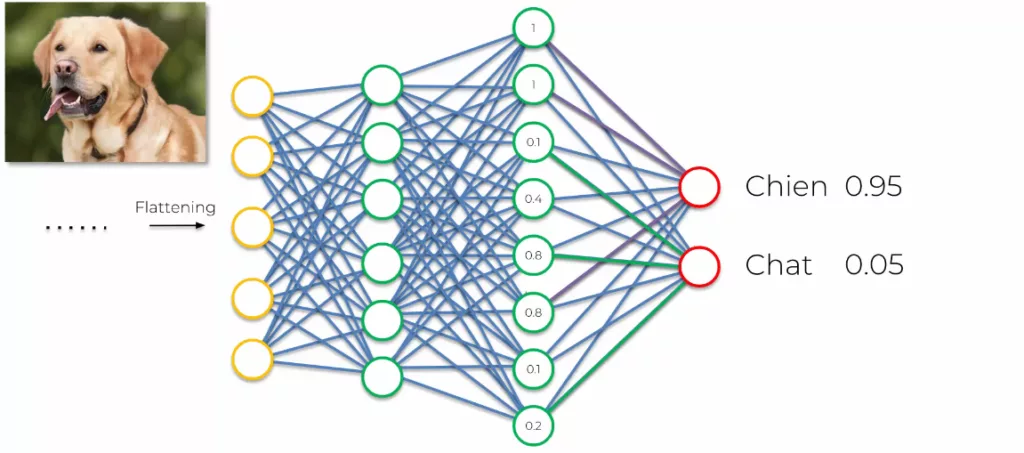
Nous retrouvons la forme de notre réseau de neurone comme expliqué dans le premier article. Les deux neurones de sortie permettent de déterminer la valeur y (chien ou chat).
Le réseau est autoapprenant en supervision, ce qui signifie que si nous montrons une image de chien et que le réseau dit chat, alors nous indiquons au réseau qu’il a faux. Ainsi, il va se réajuster lui-même en modifiant ses paramètres pour éviter la même erreur.
J’espère que cela t’a éclairé davantage sur la composition et le fonctionnement des réseaux de convolutions. C’est ce système qu’utilise la reconnaissance faciale chez Facebook, à une voiture de comprendre les panneaux ou toute autre machine capable de comprendre son environnement.
Dans le prochain article, je parlerai de comment fonctionne un réseau de reinforcement learning, une machine capable d’apprendre depuis zéro ! Sans lui dire comment faire pour apprendre, la machine est capable de dialoguer, voir, et se déplacer juste parce que nous lui avons donné un objectif à atteindre !


