Récapitulatif des modèles d’IA
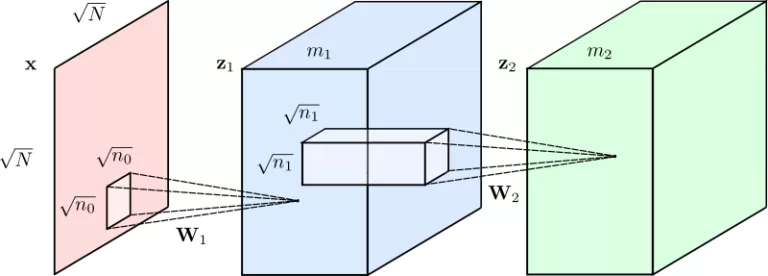
Aujourd'hui, nous entendons parler de l'IA chaque jour. Et il peut être déconcertant de ne pas tout à fait bien comprendre l'ensemble des modèles qui peuplent la jungle des intelligences artificielles. C'est la raison pour laquelle je me suis mis au défi d'écrire un article, je n'espère pas trop complexe à lire, sur l'ensemble des modèles pour que chacun puisse voir plus clair.
